


INTRODUCTION
Ça y est, vous avez un modèle de machine learning qui tourne sur votre machine et qui offre d’excellentes prédictions pour votre application. Il ne reste plus qu’à le mettre en production. Il y a cependant encore quelques étapes à effectuer avant de pouvoir l’intégrer à d’autres services.
Voici quelques questions à aborder :
- Comment s’assurer que le modèle déployé produira des prédictions identiques en production ?
- Comment dimensionner les machines et s’assurer que les latences des requêtes seront acceptables pour les serveurs applicatifs et les utilisateurs ?
- Comment adapter les ressources matérielles automatiquement lors des pics de charges ?
- Comment monitorer la qualité des modèles et créer des alertes lorsqu’il y a une déviation par rapport aux données d’entraînement ?
- Quelle stratégie employer lors du déploiement de nouveaux modèles afin d’éviter toute interruption de service ?
- Comment sécuriser les données traitées ?
Toutes ces questions s’inscrivent dans le cycle de vie MLOps qui ne se limite pas à l’étape d’entraînement des modèles (voir 1).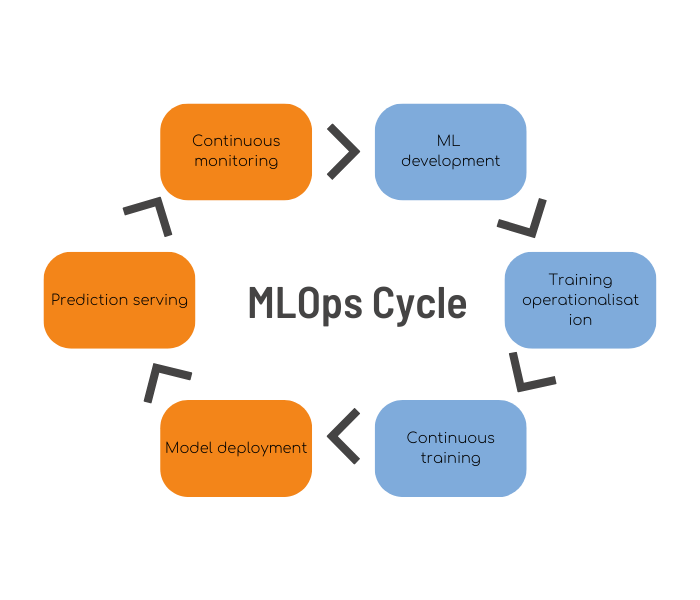
Le service Vertex AI, la nouvelle mouture du service managé de Google (auparavant nommé AI Platform), va permettre de faciliter l’adoption des bonnes pratiques MLOps.
Dans cet article nous allons voir comment implémenter les 3 parties en jaune de ce cycle : le déploiement des modèles, la création d’un service de prédiction et son monitoring. Nous allons décrire les bonnes pratiques à adopter afin d’éviter de générer de la dette technique (voir 3), et assurer une mise à jour fréquente des modèles avec une disponibilité au-delà de 99.5 %.
ARCHITECTURE : ORGANISATION EN MODÈLES, DÉPLOIEMENTS ET ENDPOINTS
|
Vertex AI utilise des images docker comme brique principale d’abstraction des modèles. Comparé à AI Platform, cela signifie qu’il est possible d’utiliser n’importe quel framework ML (et n’importe quelle version utilisée par le Data Scientist qui a entraîné les modèles) et de le coupler avec n’importe quel serveur http. Ceci permet une très grande interopérabilité du code packagé, facilitant d’une part la création d’environnements de développement et de test, et d’autre part le lancement de tests de non régression de manière automatique. Il est possible de partir d’une image déjà préparée pour Vertex AI (voir 2) ou bien de partir de n’importe quelle image docker de votre choix. |
Un modèle dans Vertex AI, c’est la combinaison de :
|
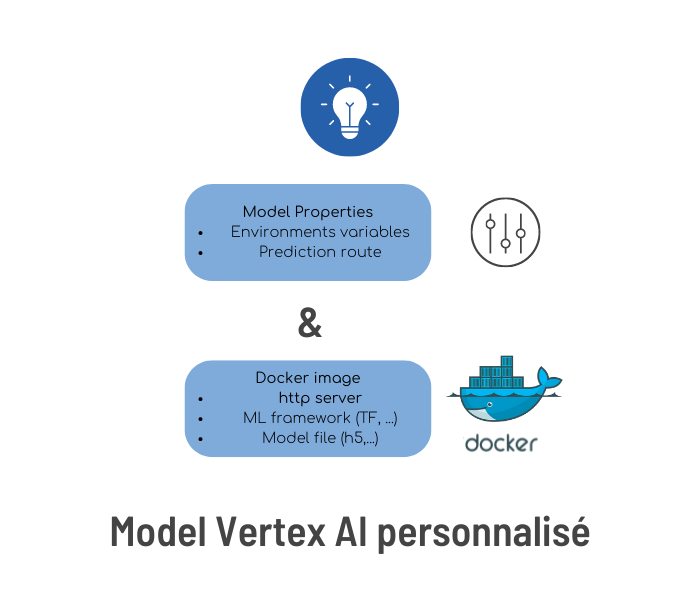
Un modèle Vertex AI peut être déployé sur un endpoint en lui associant :
- Des ressources matérielles (nombre minimum de replicas, nombre maximum de replicas, type d’instance CPU/Mémoire, accélérateur GPU, …) ;
- Un ratio correspondant à la proportion de requêtes qui seront envoyées pour prédiction vers le nouveau modèle.
Un endpoint sur Vertex AI c’est un load balancer http qui va réaliser de nombreuses opérations :
- Distribuer le trafic sur plusieurs déploiements de modèles ;
- Ajuster automatiquement le nombre de réplicas déployés en fonction du pourcentage d’utilisation CPU ;
- Réaliser un échantillonnage des requêtes afin de permettre de monitorer la qualité des modèles.
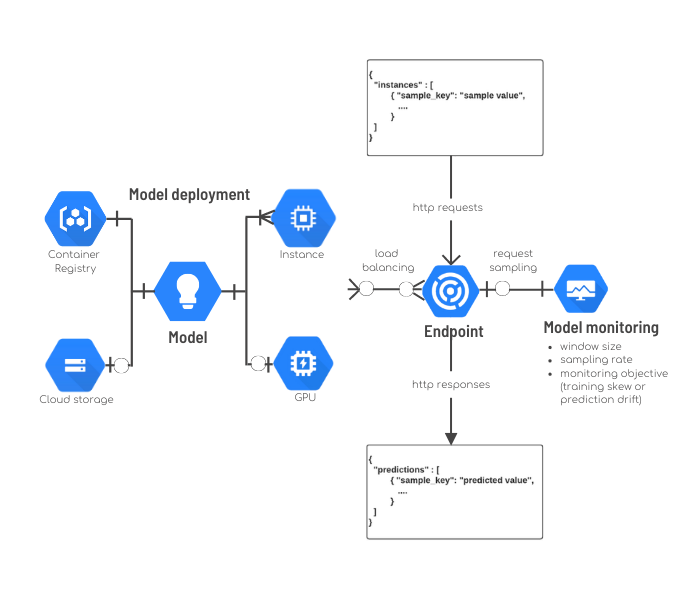
La seule contrainte imposée ici est le format des requêtes qui doit être au format JSON (un dictionnaire avec une clef par échantillon à prédire). Ce même format doit être utilisé par les serveurs http packagés dans les images docker.
— Tech Team
CYCLE ML OPS
L’architecture de Vertex AI décorrèle modèles, paramètres de configuration des modèles, ressources matérielles allouées, et proportion des requêtes routées vers les modèles déployés.
Ceci ouvre le champ à de nombreuses opérations nécessaires pour implémenter le cycle MLOps.
"IL EST AINSI POSSIBLE DE RÉALISER FACILEMENT DES TESTS DE NON RÉGRESSION, MAIS AUSSI DES TESTS DE CHARGE ET DES DÉPLOIEMENT DE MODÈLES DE TYPE A/B."
QUALITÉ DES MODÈLES : TESTS DE NON RÉGRESSION
Comment peut-on s’assurer que les modèles sont de bonne qualité et que l’on obtient les mêmes prédictions en production et dans l’environnement de développement ?
Une solution possible est de calculer des métriques de performances des modèles (voir 5), mais cela peut s’avérer parfois insuffisant lorsque les variations de prédiction sont très minimes et si elles portent sur des prédictions avec peu d’occurrences.
Sur Vertex AI, la brique de base des modèles étant une image docker, il est très simple de figer le modèle et le code associé.
— Tech Team
Ainsi, il est possible de mettre en place facilement des tests de non régression qui vont comparer les prédictions des différentes versions du modèle sur un dataset donné.
Ces tests seront joués par l’intégration continue avant chaque déploiement, et mis à jour manuellement si le test échoue.
"C’EST BIEN LA MÊME IMAGE TESTÉE ET VALIDÉE QUI SERA DÉPLOYÉE EN PRODUCTION."
Voici quelques causes possibles de variations non souhaitables qui doivent impérativement être détectées avant une mise en production :
- La simple mise à jour du framework de machine learning, de librairies ou drivers GPU peut induire des variations dans les prédictions ;
- Des règles métier sont couplées en sortie du modèle, faisant intervenir des seuils qui ont été déterminés manuellement. Ces seuils doivent être adaptés pour chaque nouveau modèle afin de produire toujours le même résultat ;
- Les scripts d’entraînement ne sont pas déterministes. Pour deux entraînements successifs, malgré des données d’entraînement identiques, les modèles obtenus sont différents. C’est généralement le signe de la présence de générateur de nombre aléatoires non contrôlés lors de l’entraînement.
Il est parfois souhaitable de figer l’initialisation des générateurs de nombres aléatoires afin d’utiliser toujours la même séquence de nombre pseudo-aléatoires.
— Tech Team
TESTS DE CHARGE
D’un entraînement à l’autre, les modèles de Machine Learning peuvent avoir des complexités assez différentes.
Ceci va avoir un impact sur le temps d’entraînement des modèles, mais cela risque aussi d’augmenter le temps d’inférence de ceux-ci (temps nécessaire pour effectuer une prédiction).
On peut donc jouer sur plusieurs paramètres afin d’assurer une latence faible pour l’utilisateur du service :
- Les paramètres internes du modèle (type de modèle, nombre de couches, taille des features) ;
- Le nombre et type de CPU alloué à une requête ;
- La quantité de mémoire allouée à une requête ;
- Le nombre minimal/maximal de réplicas ;
- Le nombre de cœurs GPU et type de GPU alloués par instance.
"EN EFFET, POUR UN MODÈLE DONNÉ, IL EST PAR EXEMPLE COURANT D’OBTENIR DE MEILLEURES PRÉDICTIONS EN AUGMENTANT LE NOMBRE DE COUCHES D’UN RÉSEAU DE NEURONES, OU BIEN LA TAILLE ET LE NOMBRE DE FEATURES UTILISÉES POUR L’ENTRAÎNEMENT."
Le meilleur compromis performance/coût peut être trouvé en effectuant des tests de charge sur un endpoint de test.
— Tech Team
Sur Vertex AI, nous avons accès à un très grand panel de machines et de types de GPU (voir 6). Nous allons pouvoir réaliser autant de modèles Vertex AI et déploiements que de paramètres, et mesurer les temps de latence des prédictions associées.
Une fois les tests terminés et le meilleur compromis trouvé, le même déploiement de modèle pourra être réalisé sur l’endpoint de production.
— Tech Team
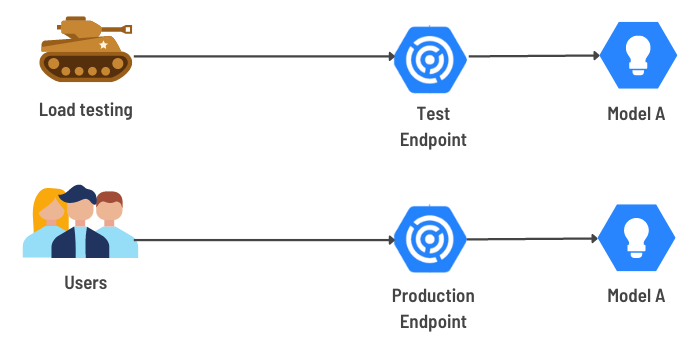
HAUTE DISPONIBILITÉ, A/B TESTING, MULTI-ARMED BANDIT TEST
Déployer un nouveau modèle sans interruption de service est souvent impératif lorsque l’on a déjà des clients qui utilisent nos services.
Vertex AI permet d’assurer une haute disponibilité des modèles déployés grâce aux replicas, mais aussi grâce au fait qu’il permet de servir plusieurs modèles simultanément sur un même endpoint.
Le déploiement d’une nouvelle version d’un modèle est donc transparent pour l’utilisateur.
— Tech Team
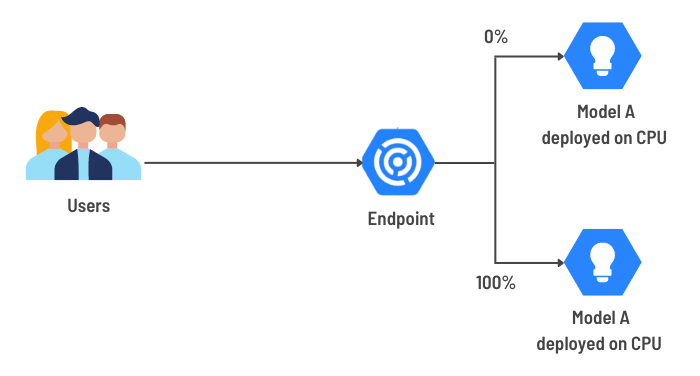
La proportion de requêtes servies par chaque déploiement peut être spécifiée à tout moment. Cela permet de réaliser un grand nombre de types de déploiements différents : rollback, tests canari, tests A/B ou multi-armed bandit tests.
Après une phase de test et une analyse statistique, le meilleur modèle permettant le meilleur taux de conversion sera sélectionné.
Dans le cas où l’on souhaiterait éviter une perte de revenu liée au temps passé par la collecte des données nécessaires pour le test A/B, on peut réaliser des tests multi-armed bandit en changeant les ratios de manière dynamique (voir 4).
"ON PEUT PAR EXEMPLE EFFECTUER DES TESTS A/B EN DÉPLOYANT DEUX MODÈLES SIMULTANÉMENT ET EN LEUR ATTRIBUANT 50% DES REQUÊTES ENTRANTES."
RE-CALCUL DES PRÉDICTIONS DES ANCIENS MODÈLES
Lors du déploiement d’un nouveau modèle, il est souvent nécessaire de recalculer l’ensemble des prédictions déjà réalisées par une version précédente d’un modèle si des prédictions sont stockées dans des bases de données.
Sur Vertex AI on peut réaliser cette opération de deux manières différentes, soit en réalisant :
- Deux déploiements avec un modèle donné et des ressources différentes : un avec un GPU par exemple qui va pouvoir traiter un très grand nombre de requêtes, et un autre moins coûteux avec des CPU. Lors de la mise en production du nouveau modèle, le re-calcul de l’ensemble des données “historiques” sera prédit par le GPU. Une fois le pic de charge absorbé, on pourra alors basculer sur le deuxième déploiement plus économique sur CPU ;
- Des prédictions par batch : Vertex AI permet d’allouer des ressources matérielles le temps nécessaire pour traiter un batch de données. La source de données en entrée peut-être soit une table BigQuery ou bien un fichier sur Google Cloud Storage.
MONITORING
Un autre point qui n’a pas encore été abordé, et qui est une grande nouveauté de Vertex AI par rapport à Platform AI, est la possibilité de monitorer les modèles.
Par monitoring, on ne parle pas seulement du nombre d’erreurs http rencontrées par le serveur, ou bien de l’utilisation CPU et du nombre d’instances matérielles utilisées.
Cela se fait en lançant régulièrement des jobs de monitoring sur une partie des requêtes d’entrée échantillonnées à cet effet par l’endpoint. Les jobs vont permettre de monitorer :
- Une déviation par rapport aux données d’entraînement ;
- Une dérive des vecteurs de caractéristiques (features) par rapport à leur distribution originale.
Une alerte peut être configurée, permettant de notifier qu’un nouveau modèle doit être ré-entraîné à cause du changement des données à prédire.
"AVEC VERTEX AI IL EST POSSIBLE DE MESURER EN CONTINU LA QUALITÉ DES MODÈLES DÉPLOYÉS."
Si l’entraînement a été automatisé, on peut même imaginer une automatisation complète du processus de ré-entraînement, validation et déploiement.
— Tech Team
SÉCURITÉ
La sécurité des services de prédiction est un aspect important lorsqu’on utilise des ressources managées.
Il faut impérativement éviter toute fuite de données qui pourrait être catastrophique pour l’image de l’entreprise et pour les utilisateurs.
— Tech Team
Heureusement il est possible d’agir sur les différentes couches réseau pour sécuriser les données traitées par Vertex AI :
Au niveau applicatif :
- Les clients font appel aux endpoints en utilisant le protocole https. Les données sont donc cryptées entre les clients et Vertex AI ;
Un service account peut-être associé à un endpoint Vertex AI et des droits peuvent lui être associés. Le code déployé ne pourra réaliser que des appels vers des ressources autorisées du projet (i.e. BigQuery, Cloud Storage, …).
Au niveau réseau
Un endpoint privé peut-être déployé. L’accès à cet endpoint se fera par une adresse privée (Network peering). Le trafic réseau ne transitera plus par le réseau public et cela permettra en plus de réduire la latence réseau.
Un périmètre de sécurité peut-être défini avec VPC Service control. Il sera alors impossible pour Vertex AI d’accéder à certaines ressources GCP, même si des jetons d’authentification d’un service account sont compromis, ou si les droits IAM du service account sont mal configurés.
CONCLUSION
Nous avons vu dans cet article tous les aspects liés au déploiement de modèles dans le cloud. Nous avons vu qu’il est possible d’utiliser Vertex AI pour rapidement déployer des modèles, ceci avec une très grande interopérabilité.
La flexibilité de ce service managé est sans comparaison avec l’utilisation de machines sur sites : on peut l’utiliser peu importe le trafic, pour des petits modèles de prédiction ou pour des traitements coûteux de NLP ou de traitement de stream vidéo. Les coûts associés peuvent-être finement contrôlés si l’on effectue correctement le dimensionnement des machines, et on peut ainsi bénéficier d’un modèle de paiement au fur et à mesure de sa consommation.
Dans un prochain article, nous verrons les autres parties du cycle MLOps, notamment la partie d’entraînement des modèles. Vertex AI permet en effet d’accélérer l’entraînement des modèles en distribuant les tâches et d’optimiser les modèles pour obtenir les meilleures performances possible. Nous aborderons également l’aspect versionnage de données.
RÉFÉRENCES
- ML Ops practitioners guide whitepaper, Khalid Salama, Jarek Kazmierczak, Donna Schut, Google Inc.
- Vertex AI pre built containers, cloud.google.com
- Hidden Technical Debt in Machine Learning systems, D. Sculley et al., Google Inc., Neural Information Processing System Proceedings, 2015
- Balancing Earning with Learning: Bandits and Adaptive Optimization, Matt Gershoff, conductrics.com, 2012
- Continuous delivery for Machine learning, Danilo Sato, Arif Wider, Christoph Windheuser, martinfowler.com, 2019
- Configurer des ressources pour la prédiction, cloud.google.com

